七月一號早上九點多,我打開 X 看到 Anthropic 的推文——才發出十三分鐘,五百五十九則回覆、一千七百多次轉貼、四千兩百八十七顆愛心。
貼文只有三句話:「我們收到通知,美國商務部已解除對 Claude Fable 5 和 Mythos 5 的出口管制。我們將從明天開始恢復存取權限,並將很快分享更新消息。」
18 天。從 6/13 早上我發現 Claude Code 狀態列跳回 Opus 4.8 那一刻算起,剛好 18 天。上一篇〈我的 Claude Code 一夜被降級〉寫的時候,我把這件事定位成「鼓吹管制的公司被自己要的刀砍中」。18 天後,刀被收回來——而且順手還多丟了一顆 Sonnet 5。
這把刀不是一口氣收回來的
我一開始以為是政府突然轉向。查了才發現不是。這 18 天分成兩段。
第一段是 6/26。商務部長 Howard Lutnick 拍板,把 Mythos 5 部分放行,允許供給 100 家以上的美國機構和聯邦政府——但只限美國境內。Fable 5 沒被鬆綁。外國人也還是被排除在外。這一步比較像試水溫,把「怎麼在符合國安條件下讓 Anthropic 繼續賣模型」的機制先跑一遍。
第二段就是 6/30 傍晚(美東時間)——Trump 政府全面解除 Fable 5 加 Mythos 5 的出口管制。Anthropic 說明天開始恢復存取。
CNBC 報導指出,官方沒有解釋 Anthropic 到底做了什麼技術或政策調整,去回應商務部原本的「防止外國人存取」疑慮。管制的時候要求隔離外國人,解除的時候沒說怎麼解決這件事,中間那 18 天發生了什麼談判、有沒有簽什麼協議——這些都沒公開。
我不腦補動機。可以講的是:Anthropic 官方的公關姿態這 18 天挺低調的,Dario Amodei 沒再發那種鼓吹強力監管的長文,Anthropic 的政策部落格也沒針對這件事表態。過去這一年他們每兩三週就會拋一次「AI 需要更嚴格國家介入」的論述,這 18 天靜音了——你要說這是巧合也可以,我覺得比較像是有意識的收斂。
同一天發 Sonnet 5 不是巧合
真正讓我看第二眼的不是解禁本身,是 Anthropic 在同一天發布了 Claude Sonnet 5。
給讀者的感覺不會是「哦,我可以繼續用 Fable 5 了」——是「哦,還多了一個新的可以用」。18 天前那則「一夜被降級」的敘事被壓下去,換成「Anthropic 的模型陣容比你被關掉之前還完整」的新說法。
規格上 Sonnet 5 也確實有話講:
- 1M token context window(跟 Opus 4.8 同級)
- 定價 $2 / $10 每百萬 token(input / output),這是介紹期價,到 8/31
- 9/1 之後回到 $3 / $15,跟 Sonnet 4.6 同價位
- 定位很直接:接近 Opus 4.8 的品質,成本大幅低
介紹期到 8/31——就是給你兩個月試用它、把工作流搬過來的窗口。6/30 解禁 + 6/30 發布 + 8/31 收攤,時間軸是一整套算好的。上次 Fable 5 的免費窗口本來排到 6/22,結果 6/12 就被政府關掉、免費期都沒走完。這次 Anthropic 把時間表壓得更緊,怕再有變數。
我在腦子裡對比了一下:Opus 4.8 的價位是 $15 / $75,Sonnet 5 介紹期的 $2 / $10 大概是它的 1/7;正式價 $3 / $15 也還是 1/5。如果 Sonnet 5 真的能接近 Opus 4.8 的品質,我用 Opus 4.8 跑的活有一大半可以搬過去。
換個角度看,Anthropic 這波不是單純降價。他們是把「原本要靠 Opus 級模型才做得動」的高階 coding agent 場景,硬拉到中價位——這對 Cursor、Windsurf、GitHub Copilot 這些吃 Claude API 的 IDE 廠商影響最直接:同樣的成本可以放給更多用戶、或者拿去打價格戰。
當然,「接近 Opus 4.8」是行銷話。Anthropic 說什麼是一回事,實測是另一回事。所以看下面兩張圖比較重要。
兩張圖裡藏了什麼
Anthropic 這次發 Sonnet 5 附了兩張 benchmark 對照圖:一張 FrontierCode v1,一張 CursorBench。橫軸都是每個任務的平均成本(美元、log scale),縱軸是分數(%),每條線一個模型,每個節點是不同的 reasoning effort(low / med / high / xhigh / max)。
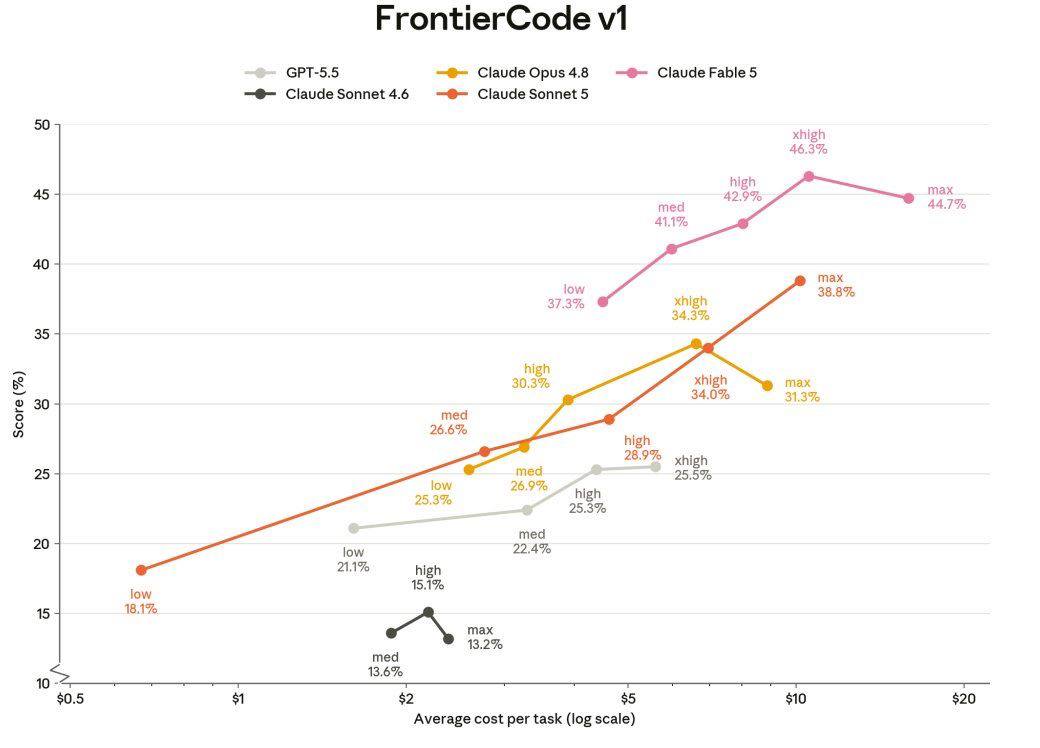
先看 FrontierCode v1。
Sonnet 5 是紅色那條線,從最左邊 low 18.1% 一路推到 max 38.8%——這個尾巴超過了 Opus 4.8 的 xhigh 34.3%。同一張圖裡的 Sonnet 4.6(黑色線條)縮在最下面 13-15% 之間,Sonnet 5 相對它跳了兩倍以上。這不是同代升級,是換代。
黃色的 Opus 4.8 走到 xhigh 拉不上去,reasoning effort 開到 max($8.94/task)反而掉回 31.3%。花更多錢分數卻更差。這種曲線在 xhigh 就轉折的模型,代表 max 檔位可能有 over-thinking 的副作用。
Fable 5(粉紅色)在最右邊。low 37.3%、med 41.1%、high 42.9%,xhigh 拉到 46.3%——這是整張圖的頂點。但這裡有個細節值得留意:Fable 5 的 max 是 44.7%,反而低於 xhigh 的 46.3%。這個「最貴不是最好」的現象在 Opus 4.8 上也出現了。開到最極致的 reasoning effort 不一定划算。
GPT-5.5 的線在中段(灰色),最高 xhigh 25.5%——被 Anthropic 這批模型全線壓在下面。如果你這幾週有感覺到部分 IDE 對 Claude 的權重變高,這張圖提供了一個可能解釋,也是 Anthropic 想重新奪回的 coding IDE 預設模型位置。
等等——為什麼對照的是 GPT-5.5,不是 6/26 才發的 GPT-5.6?OpenAI 那天發了三個型號(Sol、Terra、Luna,旗艦是 Sol),但目前只給 20 家組織 limited preview。原因是依美國政府要求走 pre-approval 流程——跟 6/12 前 Fable 5 被卡的是同一套機制。OpenAI 到現在只公開一項 benchmark 分數(Terminal-Bench 2.1: Sol 88.8%),FrontierCode 和 CursorBench 都沒有 GPT-5.6 可以對。所以 Anthropic 這波用 5.5 對照不是選擇性避戰,是 5.6 沒東西可對。
順便說一句:18 天前砍到 Anthropic 的那個機制,現在也正把 OpenAI 套進去。
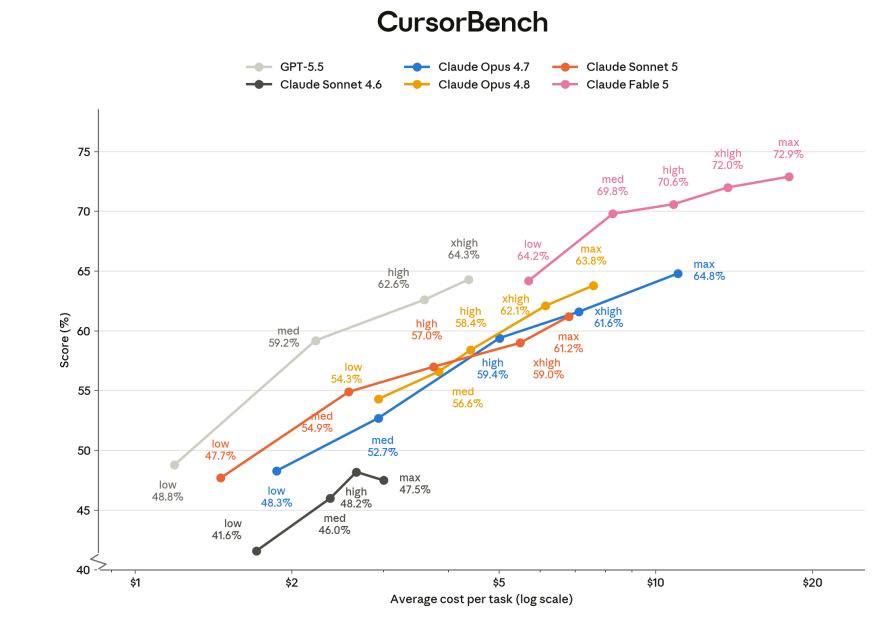
CursorBench 的排列有點不一樣。
Sonnet 5(紅色)從 low 47.7% 走到 max 61.2%。Opus 4.8(黃色)從 low 54.3% 到 max 63.8%。這兩條在最右邊差距只有 2.6%,但 Opus 4.8 的 max 成本大約 $8/task,Sonnet 5 的 max 大概是 $7/task——同樣是 max 檔位,Sonnet 5 便宜、只差 2.6%。如果你用 Opus 4.8 跑批次任務,這 2.6% 值不值那多出來的一倍多定價,我覺得多數場景是不值得的。
Fable 5(粉紅色)依然壓頂——low 就 64.2%,max 72.9%。它在 CursorBench 拉開的差距比 FrontierCode 還大。
GPT-5.5 在中段,Sonnet 4.6 卡在最下面 41-47%。這兩張圖放在一起看,Sonnet 4.6 已經不算今日陣容裡的選項了——你如果還在用它,Sonnet 5 幾乎是無腦升級。
但我要打的但書:這是 Anthropic 自己發的對照圖。CursorBench 是 Cursor 官方 benchmark,還算獨立第三方;FrontierCode v1 我查了公開報導,Sonnet 5 的 38.8% 有交叉驗證,Fable 5 的 46.3% 和 CursorBench 的 72.9% 目前只有 Anthropic 的圖表數字。等 Artificial Analysis 這種獨立 benchmark 平台補上,才知道真實水準有沒有落差。
18 天我怎麼過的
回到我自己這 18 天。
Claude Code 的狀態列從 Fable 5 跳回 Opus 4.8 之後,工作沒停。Opus 4.8 就是它的名字暗示的——五月底才發的最新版 Opus,本身是很強的模型。前傳裡我寫「用過 Fable 5 那三天再回來,落差是真的存在」,這句話 18 天後我還是這樣覺得,但落差沒有大到我做不下去。
真實影響有兩塊。
一塊是「本來想跑但延後」的活。Fable 5 那三天我開了兩個大型專案稽核,都是那種要它讀完整個 codebase、給我一份漏洞和架構問題清單的活。Fable 5 走了之後,我把類似規格的第三個專案稽核從 to-do 拉下來,改成「等模型回來再做」。這 18 天它一直躺著沒動——不是做不到,是我知道 Opus 4.8 會做得比較保守、比較容易漏掉深層的問題,我不想拿一份「還可以但不夠銳利」的稽核報告出去。
另一塊是心裡的一個小算盤。每次要開一個 Ultracode session 之前我會停一秒——「這個活值得花這個錢嗎?」這個問題以前我不太問,Fable 5 免費期我更沒問過。18 天下來我發現自己在 Ultracode 上的使用量掉了大約 60%,週限制大部分時間停在 50% 左右——上次是三天燒掉 70%。
這不是 Anthropic 希望的用戶行為。他們希望你上癮。18 天前寫完那篇文,我以為自己會很快回到原本的節奏,結果沒有——一次靜默的斷供,改的不是我對這個工具的評價,是我對它的依賴度。
這次是還回來,但刀還在
CNBC 那個沒被回答的問題我很在意:Anthropic 做了什麼技術或政策調整,讓商務部收手?
沒說 = 我無從評估「同樣的事下次會不會再發生」。管制解除不是因為 Anthropic 修好了什麼具體的東西,比較像是政治風向轉了。政治風向轉一次,也可以再轉回去。
前傳我列了三條開發者該學的(adapter 層、本地模型天花板、模型可觀測性)。這 18 天我做完的只有第三條——第一條有起頭但沒收尾,第二條完全沒動。老實說,這 18 天雖然痛但沒痛到讓我停下手邊的專案去做架構重構——這就是為什麼「當工具還在的時候動」比較難,你會覺得沒那麼急。
現在 Sonnet 5 一發布,我心裡的算盤又打得快了。Sonnet 5 的定價擺在那,我下週會拿手邊三個原本用 Opus 4.8 的中量級任務去測——如果 Sonnet 5 能接得住 80%,剩下 20% 才動用 Fable 5 或 Opus 4.8,成本大概會掉一半。
但這個算盤本身,就是我還沒學會的那一課。我又把「哪個模型效能最好、最省錢」這件事排在「adapter 層什麼時候動」前面。刀被收回來的第一天,我又開始討論怎麼更兇地用這把工具。
明天早上
寫到這裡是七月一號早上十點。明天早上——按 Anthropic 的說法——我打開 Claude Code 會看到狀態列跳回 Fable 5。或者也可能是 Sonnet 5,看 Claude Code 這邊怎麼設預設。
我不會像三週前那樣三天燒 70%。這件事是真的。
但我也不會停下 Anthropic 這條線去試別家。Sonnet 5 的定價和那兩張圖太甜了,我知道自己會被拉回去。
上一篇結尾我寫「下次做技術選型,benchmark 分數我還是會看,但有兩欄我會補上去:一欄是這東西哪天會不會突然不見,另一欄是我餵進去的東西它留多久。」這兩欄我到現在也還沒真的補進工作流裡——我只是知道應該補。
18 天前那把刀被收回來了,順手還多送我一顆 Sonnet 5。我這一課學得不夠深,Anthropic 也很清楚。